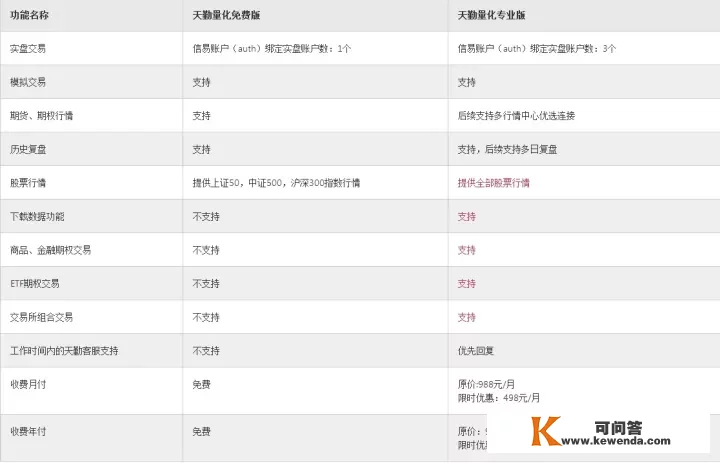
2020年8月,tqsdk原先完全免费的浩瀚机能将要收费项目(见上奏)。系遇,怨声载道。此中本栏在演示盘以及日常生活的大盘监控中也多量接纳了天勤的统计数据阅读机能。历经几番研究,本栏发现统计数据方面,天勤此次收费项目只不外影响其实不大,并没有封死完全免费的豁口。本栏目前仍然能够每晚预览并监控S场28个品种的低频统计数据,并且因为强化了营业流程,工做效率比畴前更高了。上面,我就把我的做法写出来。
奇妙就在get_kline_serial 那个他们用以订户k线的指示中,关于它的两个入参 data_length,文件文件格局中是那么说的:
data_length (int): 需要以获取的字符串宽度。预设200根, 回到的K线字符串统计数据从现阶段新一代两根K线起头往下取data_length根。 每一字符串最小全力撑持许诺 8964 个统计数据
天勤很良知的在每一团线订户的时候就发送给他们开展史上前段时间的8964个周期性的统计数据。让他们用几段标识符来看一看那些统计数据长如何:
from contextlib import closing from tqsdk import TqApi, TqSim, TqAccount, TqBacktest, TargetPosTask, TqKq import numpy as np import pandas as pd import math import tqsdk import time import copy api = TqApi(TqKq(), auth="aaaaaaaa,bbbbbbbbbb") klines_a60 = api.get_kline_serial(KQ.i@DCE.jd, 60, 10000) print(klines_a60) # 接纳with closing监视机造包管谢鲁瓦顺利完成后释放出来相联系关系的天然资本 with closing(api): while True: break获得如许两个DataFrame:
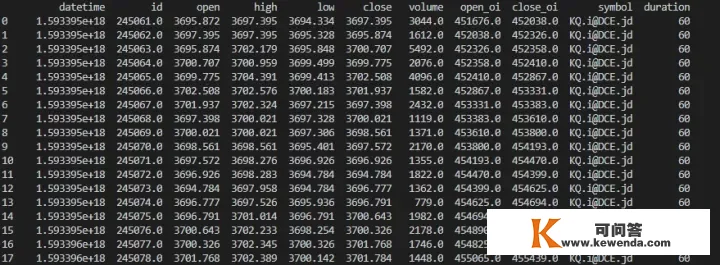
看去呢有点儿面熟…..
他们看一看用DataDownloader阅读的完全不异统计数据:
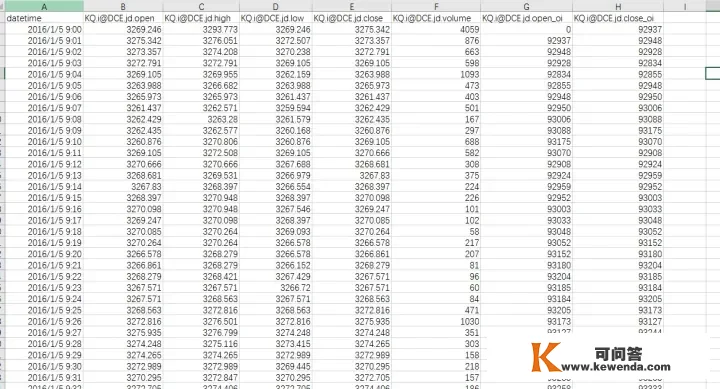
实锤了!get_kline_serial回到的k线统计数据只不外包容了DataDownloader阅读统计数据的大部分重要信息!
完全不异之处是:
index完全不异;datetime文件格局完全不异;入选为完全不异回到统计数据多了“id”、“symbol”、“duration”等列试著用下列标识符批改回到的dataframe:
from datetime import date, datetime, timedelta from contextlib import closing from tqsdk import TqApi, TqSim, TqAccount, TqBacktest, TargetPosTask, TqKq import numpy as np import pandas as pd import math import tqsdk import time import copy api = TqApi(TqKq(), auth="aaaaaaaa,bbbbbbbbbb") klines_a60 = api.get_kline_serial(KQ.i@DCE.jd, 60, 10000) klines = copy.deepcopy(klines_a60) rr = [] for i in range(len(klines[datetime])): rr.append(datetime.fromtimestamp(klines[datetime].iloc[i]/1e9)) aaaa = pd.DataFrame(rr) aaaa.columns = [datetime] klines.drop(datetime, axis=1, inplace=True) klines.drop(id, axis=1, inplace=True) klines.drop(symbol, axis=1, inplace=True) klines.drop(duration, axis=1, inplace=True) klines = pd.concat([klines, aaaa], axis=1) klines.index = klines["datetime"] klines.drop(datetime, axis=1, inplace=True) rr = [] for x in klines.columns: rr.append(KQ.i@DCE.jd+"."+x) klines.columns = rr print(klines) # 接纳with closing监视机造包管谢鲁瓦顺利完成后释放出来相联系关系的天然资本 with closing(api): while True: break成果如下:
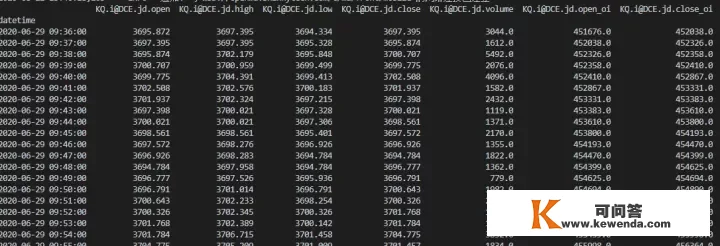
呢和DataDownloader的阅读内容一模一样了?既然如斯,连系收费项目前阅读的开展史统计数据,他们就能够试著增量预览了:
#读取开展史统计数据 datas = pd.read_csv("xxx.csv", index_col="datetime") datas.index = pd.DatetimeIndex(datas.index) #append新统计数据 datas = datas.append(klines) #去重 data = datas[~datas.index.duplicated(keep=first)] #保留 data.to_csv("xxx.csv")把那个脚本扩大到多品种并写成按时使命,就能便利的预览统计数据了!3s及以上周期性的K线,只需要每晚预览一次,2s的K线,需要迟早各预览一次,最极端的情况,若是想保留tick统计数据的话,8964根tick相当于4400多秒的时长,每个一小时预览一次是比力合理的。本栏那里因为只接纳分钟线,所以保留成csv足够了,工做效率也不慢,预览28个品种的日统计数据大约2分钟,瓶颈次要在硬盘IO,专业用户能够试著统计数据库等更高效的体例。